[ tesseract OCR, pytesseract 설치 및 사용방법 ]
Tesseract OCR (광학 문자 인식) 소개
Tesseract OCR은 이미지나 스캔된 문서에서 텍스트를 자동으로 인식하고 추출하는 데 사용되는 오픈 소스 OCR 엔진입니다.
원래는 HP 연구소에서 개발되었으며, 후에 구글에 인수되어 오픈 소스로 공개되어 사용이 가능합니다.
다양한 언어를 지원하며 높은 정확도를 자랑하며, 이는 빠른 및 자동화된 문서 처리, 검색 가능한 문서 생성, 데이터 마이닝, 자연어 처리 등과 같은 다양한 분야에서 유용하게 사용됩니다.
왜 Tesseract OCR을 사용해야 하는가?
- 무료 및 오픈 소스 : Tesseract OCR은 무료로 사용 가능하며 오픈 소스로 개발되어 커뮤니티에 의해 지속적으로 개선되고 있습니다.
- 다양한 언어 지원 : Tesseract OCR은 여러 언어를 지원하며 다양한 환경에서 텍스트를 추출할 수 있습니다.
- 높은 정확도 : 최신 버전의 Tesseract는 딥 러닝을 기반으로 하여 높은 정확도를 제공합니다.
Tesseract OCR 설치
Windows :
1. Tesseract OCR을 공식 GitHub 페이지 에서 최신 릴리스를 다운로드하고 설치합니다.
필자는 현재 가장 최신버전 (24.01.04 기준) tesseract ocr 5.3.3 버전 을 설치하였습니다.
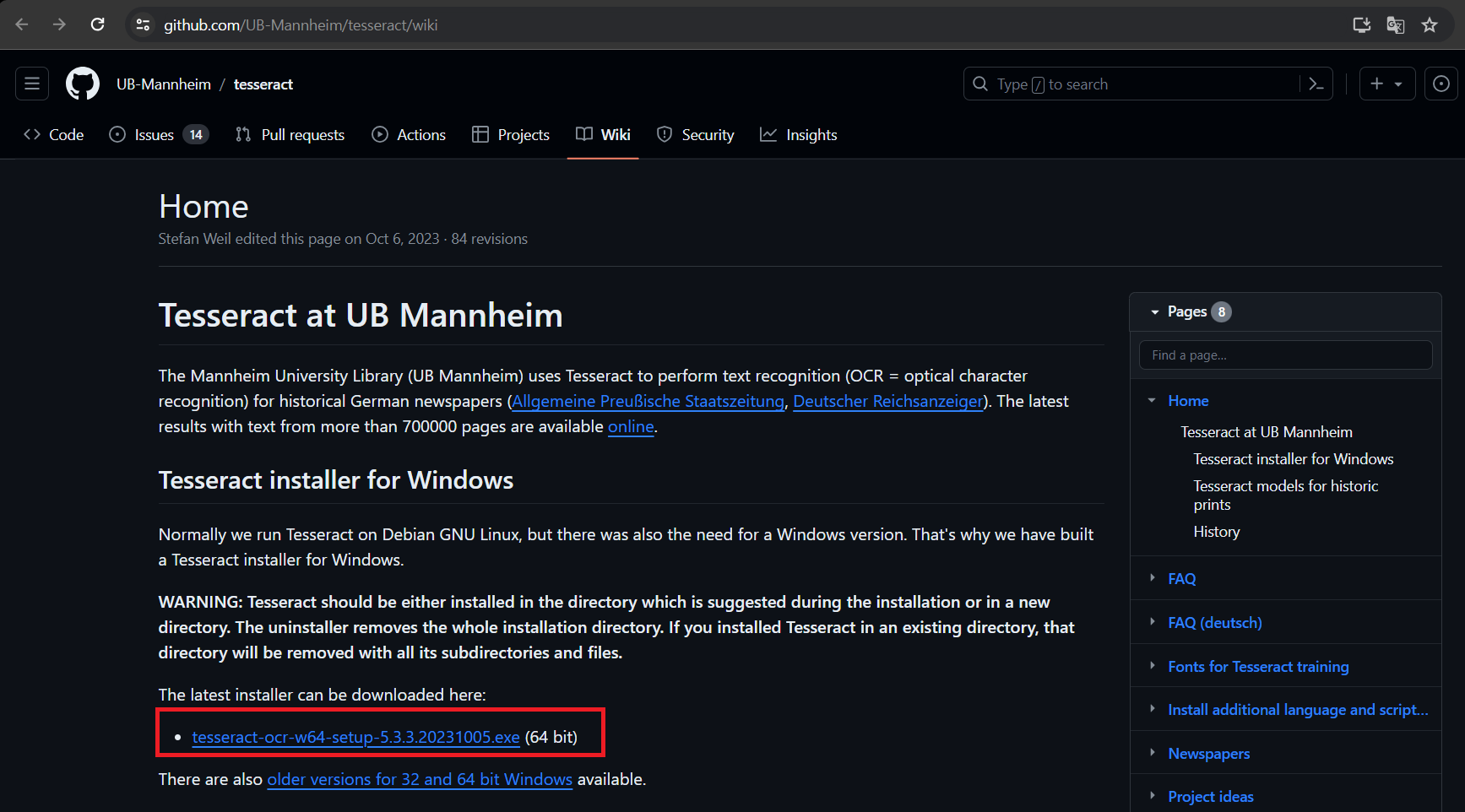
2. 설치파일을 실행시켜 줍니다.


[Additional language data] 에서 [Korean]을 추가해 줍니다. ( ABC 순서로 나열된 게 아니어서 잘 찾아야 됩니다..!! )

필요한 언어를 체크해 주고, 설치를 이어서 완료합니다.

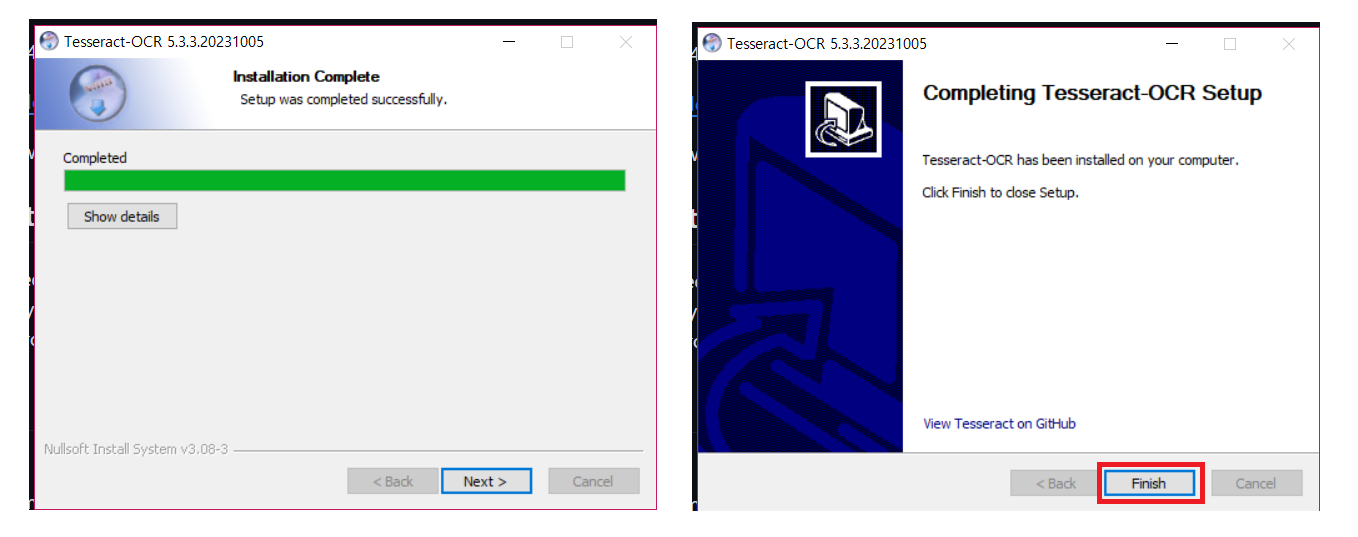
( + ) Tesseract를 시스템 환경 변수에 추가하도록 선택합니다.
5.0 이전 버전에는 환경변수에 Path를 추가하는 옵션이 있었는데, 자동으로 추가할 경우 일부 문제가 있어서 5.0 버전부터는 없어졌습니다. Python에서 직접 경로를 입력하여 호출할 거라면 Path를 추가하지 않아도 되지만 아니라면 수동으로 추가가 필요합니다.

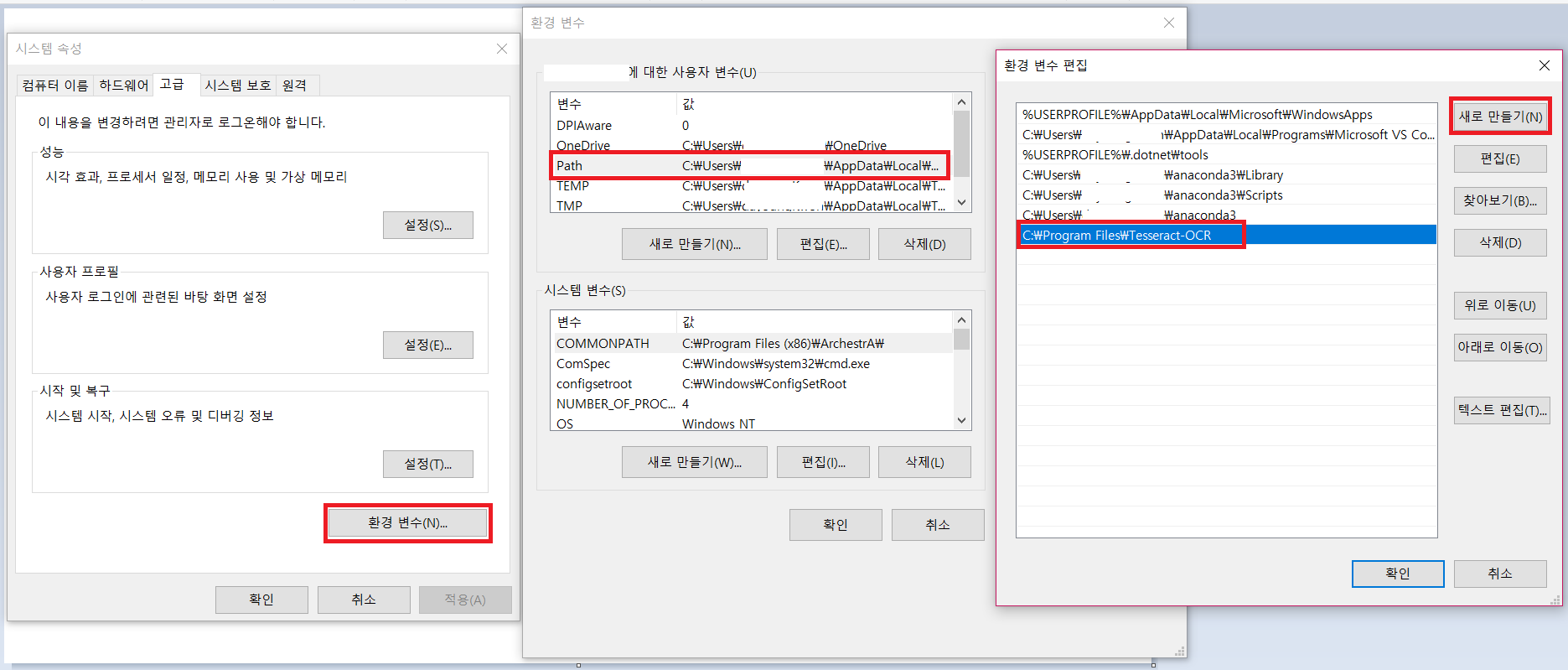
3. 마무리 단계로 Tesseract 설치를 확인합니다.
명령 프롬프트(Windows PowerShell)를 열고 'tesseract --version' 명령어를 실행하여 설치가 올바르게 되었는지 확인합니다.
macOS :
1. Homebrew를 이용하여 설치합니다. 터미널을 열고 다음 명령어로 Homebrew를 설치합니다.
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install.sh)"
2. 그 후, Tesseract OCR을 설치합니다.
brew install tesseract
3. 터미널에서 'tesseract --version' 명령어를 실행하여 설치가 정상적으로 이루어졌는지 확인합니다.
Linux (Ubuntu 기준) :
1. APT를 이용하여 설치합니다. 터미널을 열고 다음 명령어를 사용하여 Tesseract OCR을 설치합니다.
sudo apt-get update
sudo apt-get install tesseract-ocr
2. 필요한 언어 데이터를 설치합니다. 예를 들어, 한국어 데이터를 설치하려면 다음과 같이 작성합니다.
sudo apt-get install tesseract-ocr-kor
3. 터미널에서 'tesseract --version' 명령어를 실행하여 설치가 올바르게 되었는지 확인합니다.
설치가 완료되면 Tesseract OCR을 활용하여 이미지나 스캔된 문서에서 텍스트를 추출할 수 있습니다.
사용할 언어에 따라 필요한 언어 데이터도 추가로 설치할 수 있습니다.
필자는 '한국어' 데이터를 추가하였습니다. kor.traineddata 파일을 다운로드하여 tessdata 경로에 넣어주었습니다.
▼ 경로(Tesseract-OCR경로에 tessdata 폴더 내) : C:\Program Files\Tesseract-OCR\tessdata
파일 다운로드 github 주소 : https://github.com/tesseract-ocr/tessdata/blob/main/kor.traineddata

기존에 kor.traineddata가 있을 수도 있는데 처음에는 1,xxxKB 크기의 파일이 있습니다.
github에서 파일을 받아서 수정해 주면 14,xxxKB 크기의 파일로 변경됩니다. 파일 크기를 확인해 주세요!!
'Dev etc > etc' 카테고리의 다른 글
| 📌 개발 방법론 종류와 특징 정리 (프로젝트 성격별 추천 포함) (0) | 2025.06.04 |
|---|---|
| [Web-dev] URL 인코딩(Encoding)이란? 기본원리 및 사용 예제 (0) | 2024.06.12 |
| [C++] 콘솔환경에서 글자색,배경색 색상 변경 (0) | 2023.09.21 |
| [Docker] 도커 컴포즈(Docker Compose)란 ? (0) | 2023.06.23 |
| [Docker] 도커 이미지(Image)와 컨테이너 (0) | 2023.06.19 |

댓글