Titanic - Machine Learning from Disaster | Kaggle
www.kaggle.com
타이타닉 탑승자 정보 데이터를 가지고,
"어떤 종류의 사람이 생존할 가능성이 높은가?" 라는 질문에 답하는 예측 모델을 구축해 봅시다!
필자는 Google colab에서 실행하였다.
따라서 Data에서 훈련세트, 테스트세트 Dataset을 받아서 해당파일 경로에 넣어주었다.
[ 훈련세트 필드명 확인 ]
- survived : 생존=1, 죽음=0
- pclass : 승객 등급. 1등급=1, 2등급=2, 3등급=3
- sibsp : 함께 탑승한 형제 또는 배우자 수
- parch : 함께 탑승한 부모 또는 자녀 수
- ticket : 티켓 번호
- cabin : 선실 번호
- embarked : 탑승장소 S=Southhampton, C=Cherbourg, Q=Queenstown
▶ 데이터 살펴보기
import pandas as pd
from pandas import Series, DataFrame
import numpy as np
train_df = pd.read_csv("train.csv")
test_df = pd.read_csv("test.csv")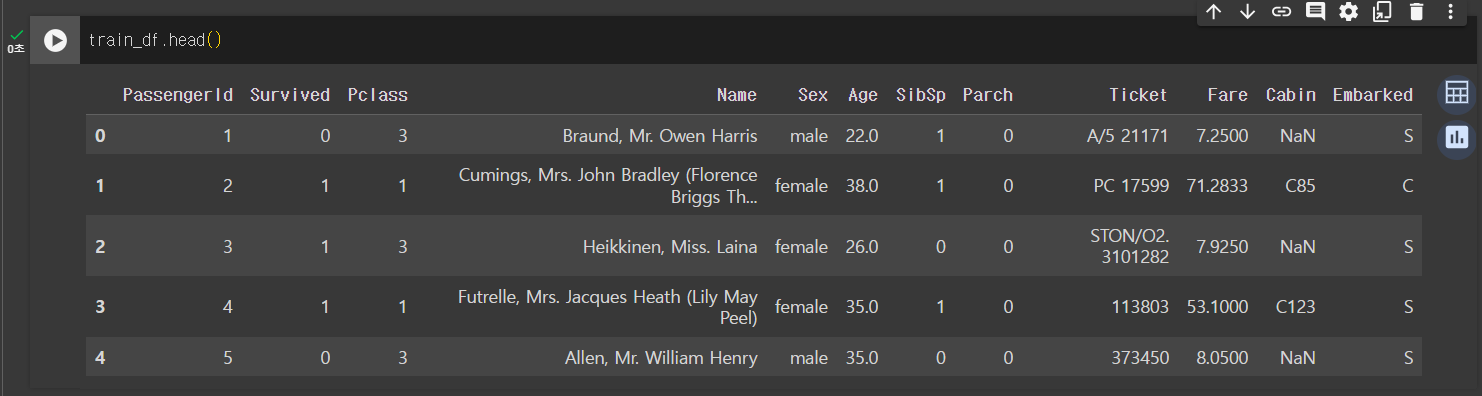
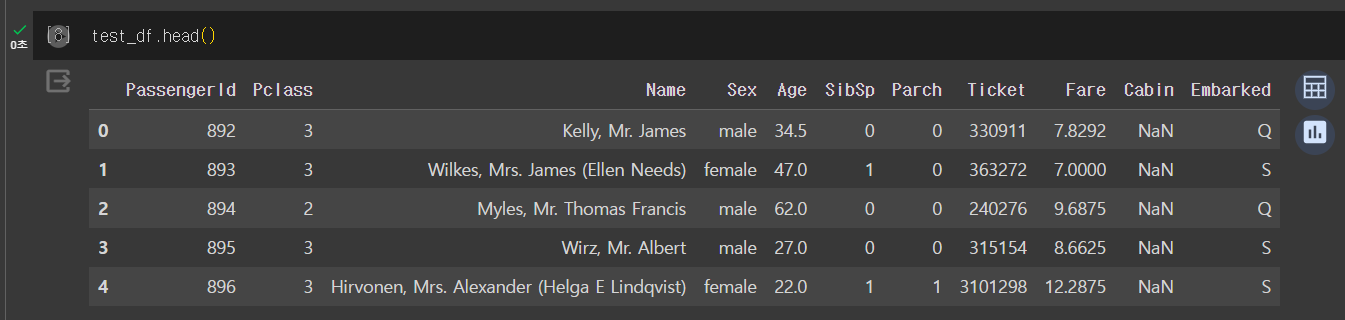
train 데이터에는 Survived 가 포함되어 있고 test 데이터에는 없다.
test 파일을 예측하여 각 PassengerID의 Survived 를 예측하여 제출하는 문제인 것을 알 수 있다.
> train 정보 살펴보기
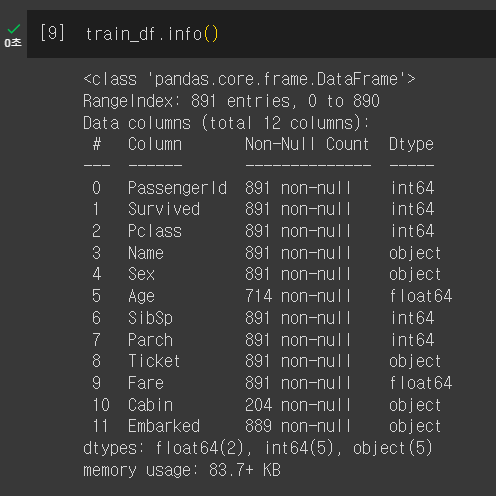
총 891건 중 Age, Cabin, Embarked 는 정확한 정보를 갖고 있지 않음을 확인할 수 있다.
> 데이터 시각화하여 특징 분석하기
import seaborn as sns
import matplotlib.pyplot as plt
def bar_chart(feature):
survived = train_df.loc[train_df["Survived"]==1,feature].value_counts() #해당 특징의 Survived 가 1인 갯수를 세어준다.
dead = train_df.loc[train_df["Survived"]==0,feature].value_counts()
df = pd.DataFrame([survived,dead],index = ["Survived","Dead"])
df.plot(kind="bar",figsize=(10,5))
plt.show()#Pclass에 따른 생존/사망자 확인
bar_chart("Pclass")
1등석은 생존자가 더 많고, 3등석은 사망자가 더 많은 것을 확인할 수 있다.
따라서 Pclass 특징은 지도 학습에 가져가는 것이 좋다는 것을 판단할 수 있다.
#Fare 에 따른 생존/사망자 확인
facet = sns.FacetGrid(train_df,hue='Survived',aspect=4)
facet.map(sns.kdeplot,'Fare',shade=True)
facet.set(xlim=(0,train_df['Fare'].max()))
facet.add_legend()
plt.xlim(0,180)
plt.show()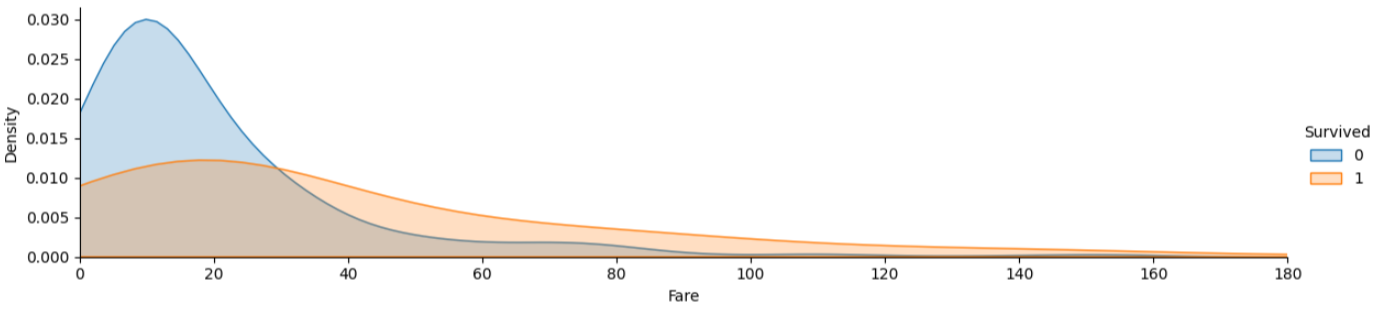
Fare(요금)가 낮을수록 사망자가 많은 것을 확인할 수 있다.
따라서 Fare도 지도 학습으로 가져가는 것이 좋다.
#Sex 에 따른 생존/사망자 확인
bar_chart('Sex')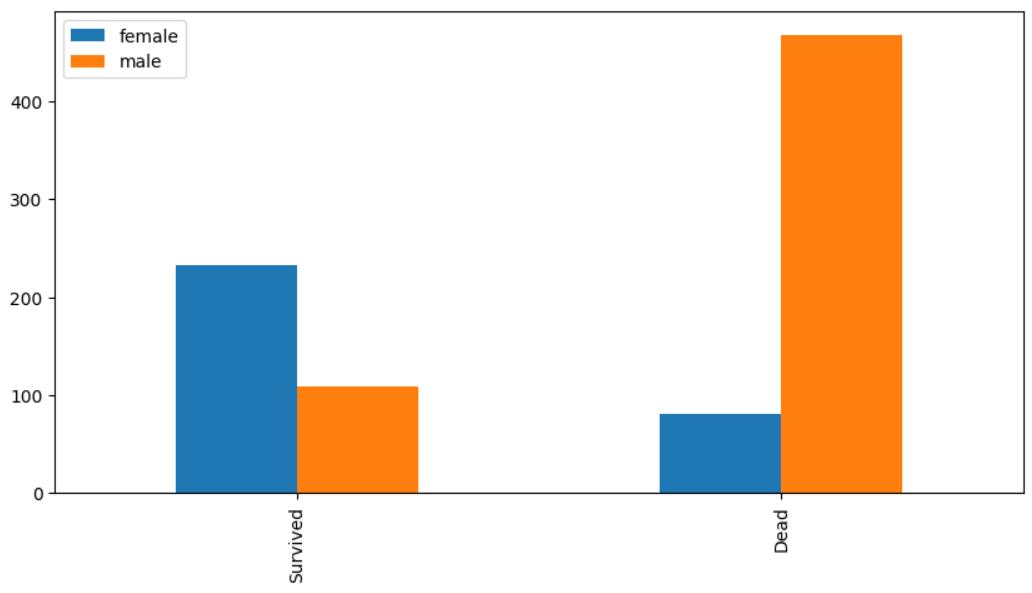
#Age 에 따른 생존/사망자 확인
facet = sns.FacetGrid(train_df,hue='Survived',aspect=4)
facet.map(sns.kdeplot,'Age',shade=True)
facet.set(xlim=(0,train_df['Age'].max()))
facet.add_legend()
plt.xlim(0,180)
plt.show()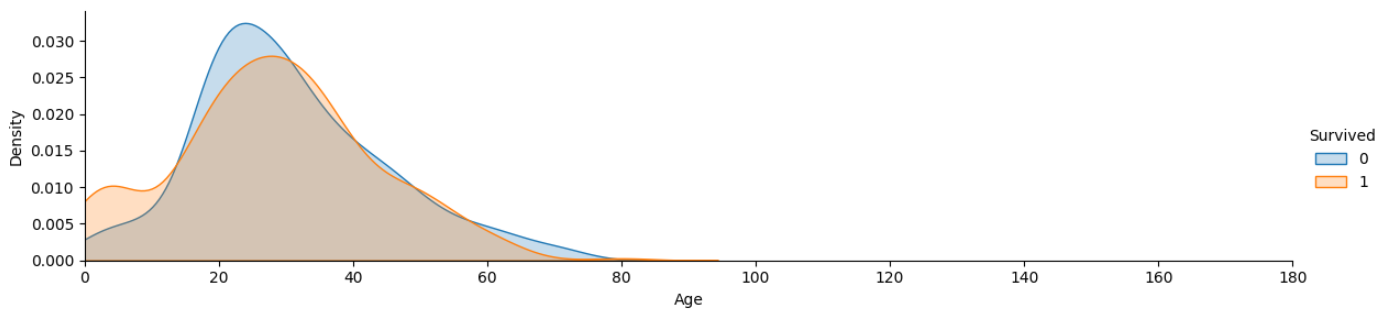
#Embarked 에 따른 생존/사망자
bar_chart('Embarked')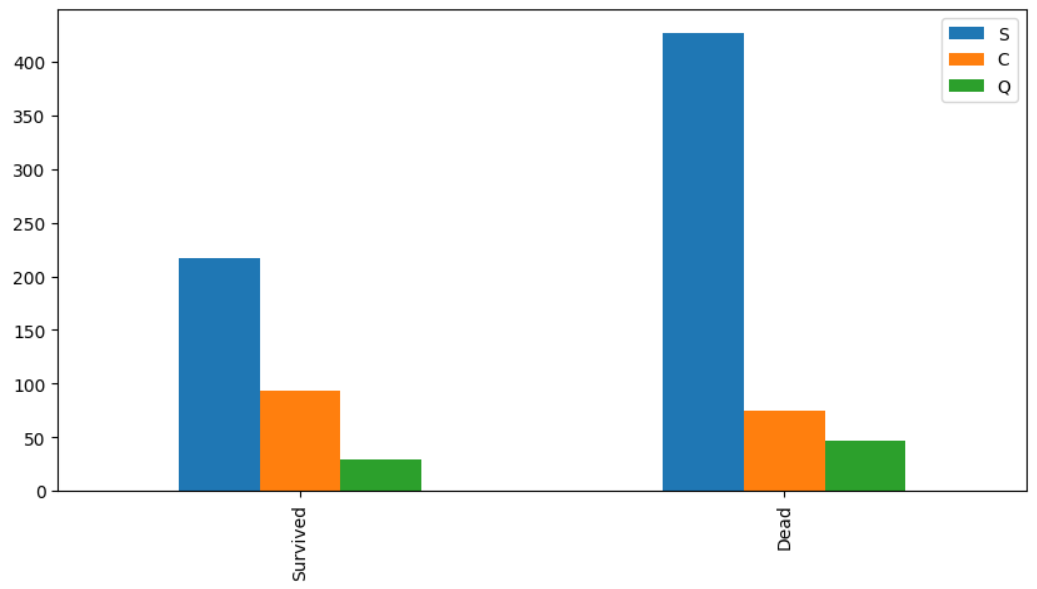
▶ 데이터 가공
NaN인 항목들은 평균으로 대체한다.
train_df["Age"].fillna(train_df["Age"].mean() , inplace=True)
test_df["Age"].fillna(train_df["Age"].mean() , inplace=True)
정보가 많지 않은 feature은 제거한다.
train_df = train_df.drop(['Cabin'], axis=1)
test_df = test_df.drop(['Cabin'], axis=1)
사용하지 않는 특징은 제거한다.
train_df = train_df.drop(['PassengerId', 'Name', 'Ticket'], axis=1)
test_df = test_df.drop(['Name','Ticket'], axis=1)
☞ pd.get_dummies() : 수치형 데이터를 범주형 데이터로 바꾸어주는 함수.
수치형 데이터로 사용할 경우 서로간에 관계가 생기기 때문에 위 함수를 사용하여 범주형 데이터로 바꾸어준다.
ex) 1 + 2 = 3
pclass_train_dummies = pd.get_dummies(train_df['Pclass'])
pclass_test_dummies = pd.get_dummies(test_df['Pclass'])
pclass_train_dummies.columns = ['first', 'second', 'third']
pclass_test_dummies.columns = ['first', 'second', 'third']
train_df.drop(['Pclass'], axis=1, inplace=True)
test_df.drop(['Pclass'], axis=1, inplace=True)
train_df = train_df.join(pclass_train_dummies)
test_df = test_df.join(pclass_test_dummies)
sex_train_dummies = pd.get_dummies(train_df['Sex'])
sex_test_dummies = pd.get_dummies(test_df['Sex'])
sex_train_dummies.columns = ['Female', 'Male']
sex_test_dummies.columns = ['Female', 'Male']
train_df.drop(['Sex'], axis=1, inplace=True)
test_df.drop(['Sex'], axis=1, inplace=True)
train_df = train_df.join(sex_train_dummies)
test_df = test_df.join(sex_test_dummies)
데이터 가공 후
위에서 지도 학습으로 적합했던 특징들을 독립변수로 하여 Survived 를 예측하는 머신러닝 모델을 만들면 된다 !
///
모델 선택, 모델 훈련, 테스트 데이터 예측은 다음 블로깅 2편에 정리예정 !!
'DB > ML' 카테고리의 다른 글
| [머신러닝] 로지스틱 회귀 (Logistic Regression) (0) | 2023.12.21 |
|---|---|
| [머신러닝] 범죄율(CRIM)로 집값 예측하기 (0) | 2023.12.20 |
| [머신러닝] 선형 회귀(Linear Regression) (1) | 2023.12.20 |

댓글